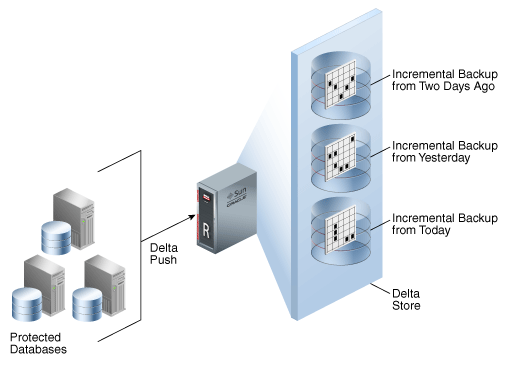
For ZDLRA, the task type INDEX_BACKUP it is important (if it is not the most) because it is responsible to create the virtual full backup. This task runs for every backup that you ingest at ZDLRA and here, I will show with more details what occurs at ZDLRA: internals steps, phases, and tables involved.
I recommend that you check my previous post about ZDLRA: ZDLRA Internals, Tables and Storage, ZDLRA, Virtual Full Backup and Incremental Forever, and Understanding ZDLRA. They provide a good base to understand some aspects of ZDLRA architecture and features.
Backup
As you saw in my previous post, ZDLRA opens every backup that you sent and read every block of it to generate one new virtual full backup. And this backup is validated block a block (physically and logically) against corruption. It differs from a snapshot because it is content-aware (in this case it is proprietary Oracle datafile blocks inside another proprietary Oracle rman block) and Oracle it is the only that can do this guaranteeing that result is valid.