One of the most knows features of ZDLRA is the virtual full backup, basically incremental forever strategy. But what this means in real life? In this post, I will show some details about that and how interesting they are, check what it is Virtual Full Backup and Incremental Forever strategy for ZDLRA.
This post is based on my previous one where I showed all the steps to configure the VPC and enroll database at ZDLRA.
Virtual Full Backup
A virtual full backup appears as an incremental level 0 backup in the recovery catalog. From the user’s perspective, a virtual full backup is indistinguishable from a non-virtual full backup. Using virtual backups, Recovery Appliance provides the protection of frequent level 0 backups with only the cost of frequent level 1 backups.
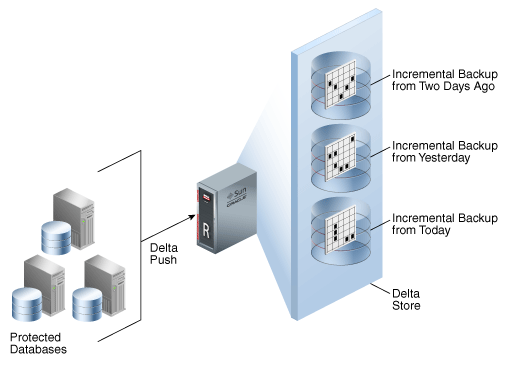
This definition (and image) are in the Zero Data Loss Recovery Appliance Administrator’s Guide and I think that represents the essence of the virtual full backup. ZDLRA receive the incremental level 1 backup, index it, and generate a level 0 to you that it is indistinguishable from a normal backup level 0.