Yes, it is a game-changer. It is for DBAs. It is for DevOps. It is for Enterprises too. And it is not because of new internal services, new ways to access data, or the scalability. But because it changes and improves a lot the way that databases can be refreshed, the way that databases are cloned, how to do CI/CD, and how to deliver databases.
Forget all the slowness and painful process when it is needed to clone production databases over lower environments, or when it is required to clone the dev database to another one. Let’s discover below what can be done with Exascale.
Exascale, the basic information
Exascale is built on top of Exadata software. So, all the software features from Exadata are there, the smartscan, the bloom filter, the resource manager, the AI Vector, the JSON, the RDMA, and the RoCE. Even details like the internal services, the MS, CS, and RS continue the same.
On top of that, comes the Exascale software. Several additional services are created to control the communication with the database and deliver the new features. Exascale can be used, deployed, and scaled the way that is needed. It can start, for example, with 300GB until hundreds of terabytes. So, scalability is not an issue.
At Exascale, the usable space is called Vault and the database clusters can share this Vault (imagine that it is the same as ASM diskgroup) to put datafiles redo’s and archivelogs. Going beyond, the storage can be shared (as block devices) by iSCSI to allow plug the Exascale into your network and facilitate the database migrations. When it is OCI, virtual machines can be booted using the Vault as a bootable device.
The communication with databases does not change too much, the Oracle database kernel talks directly with Exascale Vault. So, the first big change, ASM does not exist for 23ai and newer versions. All the redundant processes consuming CPU and memory (by ASM) are gone (imagine all the clusters of ExaCC/ExaCS/Exadata, all of them with their own ASM process). With Exascale they don’t exist anymore because, now, the databases talk directly with Exascale and the Vault. For the 19c database, the ASM is still in place. But at the same Exadata Exascale appliance can have clusters running in 23ai, and others in 19c.
This is the view of CRS for Exascale running with 23ai:
[oracle@linl11 ~]$ crsctl stat res -t
--------------------------------------------------------------------------------
Name Target State Server State details
--------------------------------------------------------------------------------
Local Resources
--------------------------------------------------------------------------------
ora.LISTENER.lsnr
ONLINE ONLINE fsi11 STABLE
ONLINE ONLINE fsi12 STABLE
ora.acfsrm
ONLINE ONLINE fsi11 STABLE
ONLINE ONLINE fsi12 STABLE
ora.ccmb
ONLINE ONLINE fsi11 STABLE
ONLINE ONLINE fsi12 STABLE
ora.chad
ONLINE ONLINE fsi11 STABLE
ONLINE ONLINE fsi12 STABLE
ora.hvvmqytk.acfs-24021923006d3fe1d.acfs
ONLINE ONLINE fsi11 mounted on /acfsmounts/oraacfs,STABLE
ONLINE ONLINE fsi12 mounted on /acfsmounts/oraacfs,STABLE
ora.net1.network
ONLINE ONLINE fsi11 STABLE
ONLINE ONLINE fsi12 STABLE
ora.ons
ONLINE ONLINE fsi11 STABLE
ONLINE ONLINE fsi12 STABLE
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
And these are the basis for Exascale, the documentation has a lot of information about the new services and other details.
Vault
To resume, Vault is where your data is stored, and where the Exascale manages it. The Exascale software spreads the database files in all Exadata storage servers and isolates/secures access between different users/clusters. The access is done by users using traditional wallets.
The reference and association are similar to an ASM diskgroup. The access is done using the “@”, instead of the “+” of ASM. And it is that. For the database point of view the datafile now will be like this: @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/CDB1/1958BAD8B27B2F85E0636039010AB112/DATAFILE/SYSTEM.OMF.54C2961A
Inside the Vault exists Datasets, which is the path where the file is stored. For databases, it follows: @Vault-name:GI-cluster-ID:CDB-ID:PDB-ID. For other types of data, the path changes. Vault is based on Exadata celldisks exposed as Storage Pools, and they can be created for each media type (EC, HP, Flash). The Vault can mix several Storage Pools, and templates can be created to redirect files to the desired storage pool inside the Vault.
Users can access and administrate in several ways. Traditional users can access to read/write, and administrators can limit resources like IOPS.
But WHY game-changer?
Let’s pick up the datafiles, inside the Vault the Exascale software sees each one of the datafile extents, hash them, and saves information about the disks where they are in one mapping table of storage buckets.
The mapping table is a simple structure inside the Exascale software that tells what is the location for each extent. A hash function determines the bucket and the Exascale software (using the mapping table) defines the locate/disk where the bucket will be written. By the mirror redundancy, each bucket is stored in several storage cells.
When a database is cloned, the Exascale software identifies the extends for the source database, and the buckets where they are, and shares access to them to the target database. The new blocks created/modified by the source (and the target database created by the clone) are written in the new places while the original (not modified ones) remain the same and continue to be shared between both databases.
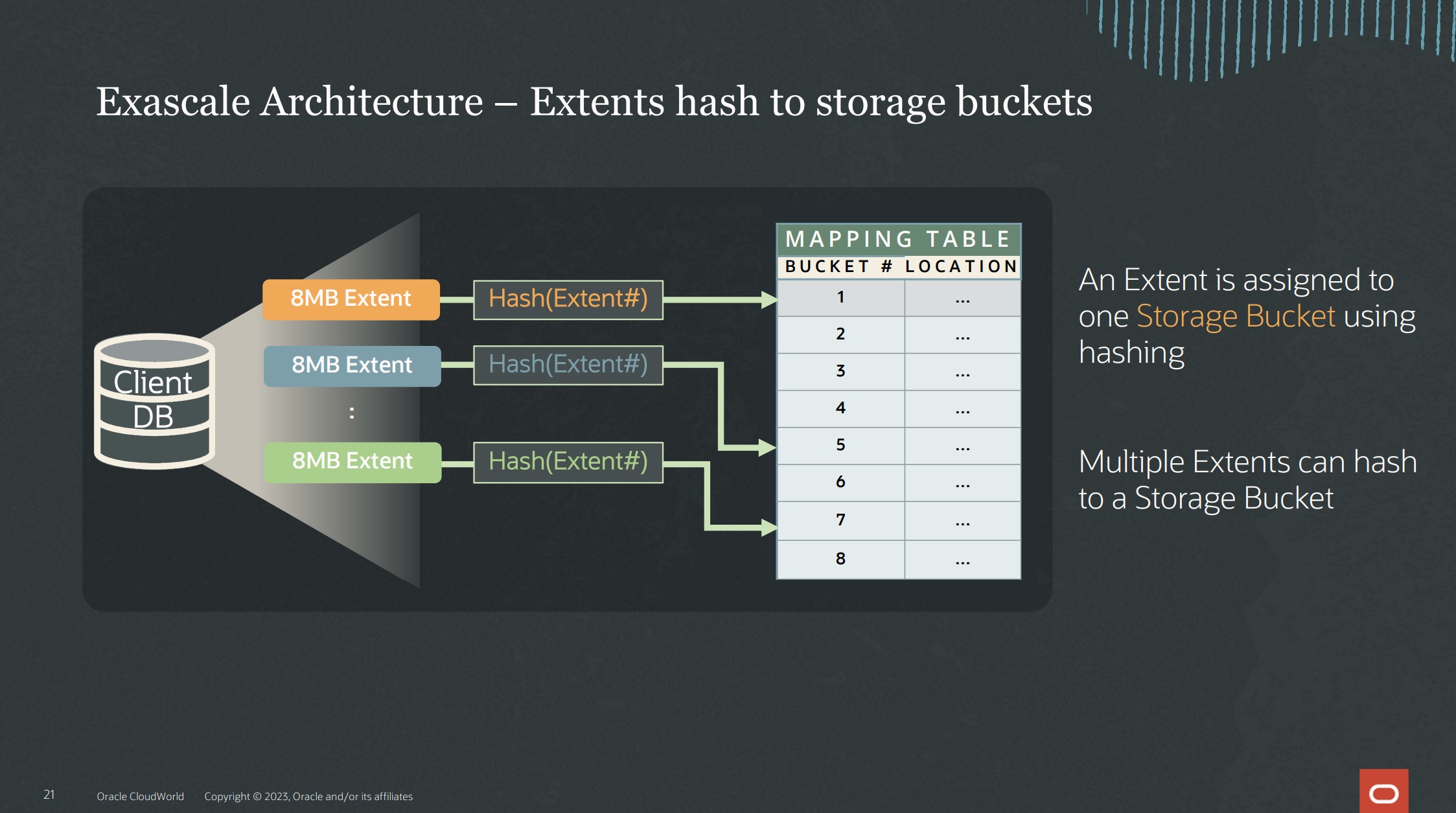
Image extracted from the presentation “Exadata Exascale: Next Generation Architecture and Technology Preview [LRN2724]” of OCW2023
So, in the end, it is not needed to copy datafiles during database clones. The process is done completely at the storage level it is just extents, buckets, and mapping table share/access. And since it is the same Vault that stores the data the source database can be in open state, receiving reads/writes. And it is not needed to create sparse diskgroups to do that.
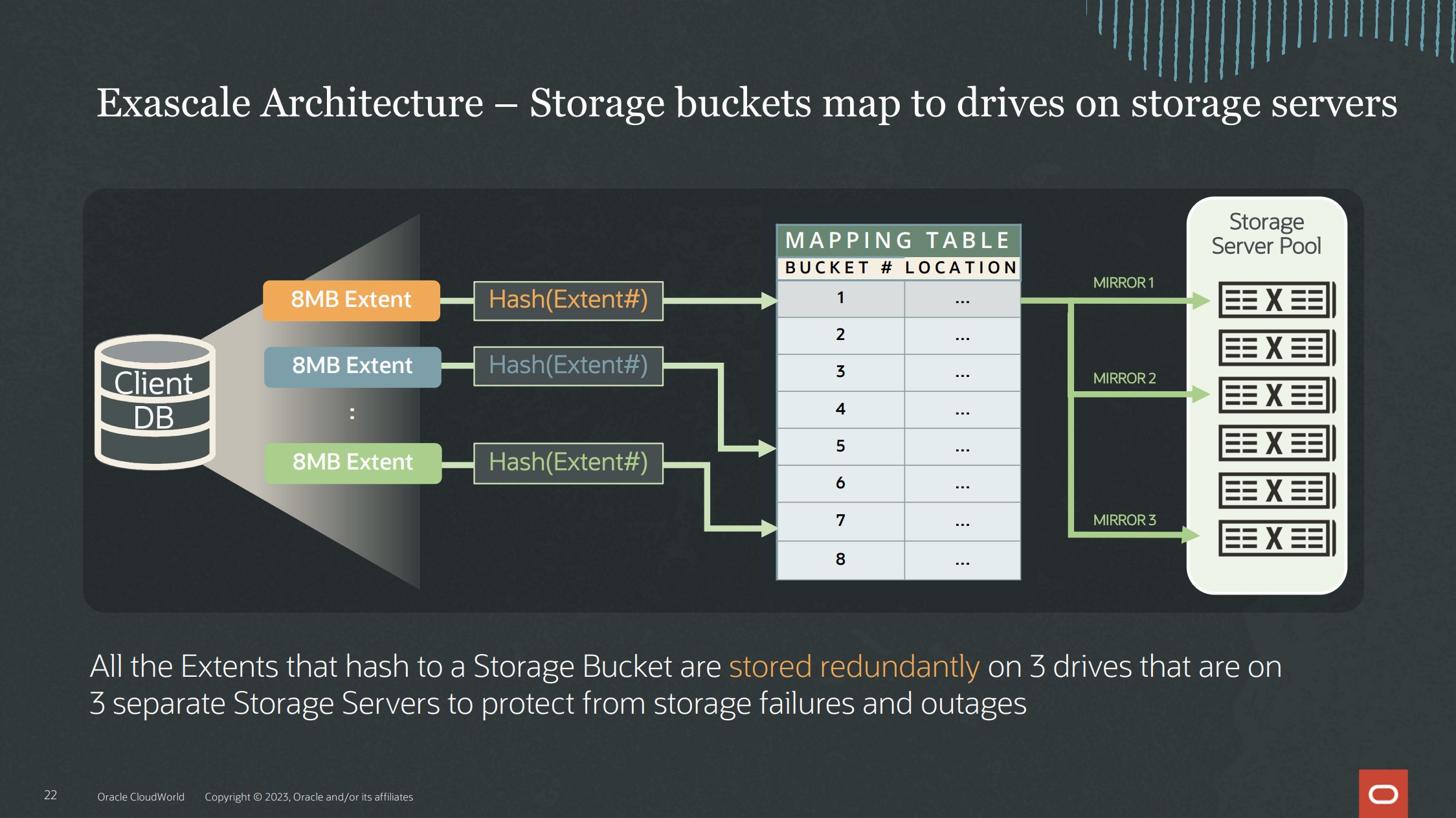
Image extracted from the presentation “Exadata Exascale: Next Generation Architecture and Technology Preview [LRN2724]” of OCW2023
Snapshot Copy
In real life this new Exascale snapshot mode works like this:
SQL> set timing on
SQL>
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 FSI1PDB READ WRITE NO
5 FSI1PDB114G READ WRITE NO
8 FSI1PDB622G READ WRITE NO
SQL>
SQL> select con_id, sum(bytes)/1024/1024/1024 as size_gb from v$datafile group by con_id;
CON_ID SIZE_GB
---------- ----------
1 5.23925781
2 .673828125
3 1.49450684
5 113.907593
8 622.129272
Elapsed: 00:00:00.01
SQL>
SQL> create pluggable database FSI1PDB114G_FULL from FSI1PDB114G;
Pluggable database created.
Elapsed: 00:02:32.96
SQL> alter pluggable database FSI1PDB114G_FULL open;
Pluggable database altered.
Elapsed: 00:00:16.18
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 FSI1PDB READ WRITE NO
4 FSI1PDB114G_FULL READ WRITE NO
5 FSI1PDB114G READ WRITE NO
8 FSI1PDB622G READ WRITE NO
SQL>
SQL> create pluggable database FSI1PDB114G_SNAP from FSI1PDB114G snapshot copy;
Pluggable database created.
Elapsed: 00:00:09.97
SQL> alter pluggable database FSI1PDB114G_SNAP open;
Pluggable database altered.
Elapsed: 00:00:10.73
SQL>
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 FSI1PDB READ WRITE NO
4 FSI1PDB114G_FULL READ WRITE NO
5 FSI1PDB114G READ WRITE NO
6 FSI1PDB114G_SNAP READ WRITE NO
8 FSI1PDB622G READ WRITE NO
SQL>
SQL> select con_id, sum(bytes)/1024/1024/1024 as size_gb from v$datafile where con_id in(4, 5, 6) group by con_id;
CON_ID SIZE_GB
---------- ----------
4 113.907593
5 113.907593
6 113.907593
Elapsed: 00:00:00.06
SQL>
Explaining what’s happened above:
- The FSI1PDB114G is the pdb #5 and has 114GB.
- It was cloned using the traditional way and took 2 minutes and 32 seconds. After was opened.
- It was cloned using the Exascale method with SNAPSHOT COPY. It took 9 seconds. After was opened.
So, this is the game-changer. Imagine refreshing entire databases in 10 seconds. 100GB cloned, available to open in read and write in 10 seconds. Imagine all the pipelines and CI/CD that can be done faster. Imagine all DevOps that can create all DEV environments in 10 seconds. Exascale can be renamed to ExaOps machine and still be accurate.
Something important to reinforce is that, now, it is not necessary to use fancy commands or Storage shares/NFSs to do the snapshot. They can be done directly from the sqlplus with one simple command. And looking at the example above, it is possible to notice that even the traditional clone, was executed online and with one command. Some Exascale optimizations (at the storage level) will help even if the conventional clone is used.
Continuing from above, the pdb FSI1PDB622G has 622GB, and when trying to clone it (as before), Exascale magic does the trick:
SQL> create pluggable database FSI1PDB622G_FULL from FSI1PDB622G;
Pluggable database created.
Elapsed: 00:16:38.27
SQL>
SQL> alter pluggable database FSI1PDB622G_FULL open;
Pluggable database altered.
Elapsed: 00:00:16.86
SQL>
SQL> create pluggable database FSI1PDB622G_SNAP from FSI1PDB622G snapshot copy;
Pluggable database created.
Elapsed: 00:00:10.01
SQL>
SQL> alter pluggable database FSI1PDB622G_SNAP open;
Pluggable database altered.
Elapsed: 00:00:12.45
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 FSI1PDB1 READ WRITE NO
4 FSI1PDB114G_FULL READ WRITE NO
5 FSI1PDB114G READ WRITE NO
6 FSI1PDB114G_SNAP READ WRITE NO
7 FSI1PDB622G_FULL READ WRITE NO
8 FSI1PDB622G READ WRITE NO
9 FSI1PDB622G_SNAP READ WRITE NO
SQL>
The gains are pretty clear. The 622GB clone in the traditional way took 16 minutes and 38 seconds. Using the Exascale SNAPSHOT COPY the same clone took 10 seconds.
Can be argued that works just inside the same CBD, but this works between different CDBs? YES! Look:
[oracle@lin11 ~]$ export ORACLE_SID=CDB11
[oracle@lin11 ~]$ sqlplus / as sysdba
SQL*Plus: Release 23.0.0.0.0 - Production on Sun Mar 24 00:36:26 2024
Version 23.3.0.23.09
Copyright (c) 1982, 2023, Oracle. All rights reserved.
Connected to:
Oracle Database 23c Enterprise Edition Release 23.0.0.0.0 - Production
Version 23.3.0.23.09
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 CDB1PDB1 READ WRITE NO
SQL>
SQL> CREATE DATABASE LINK clone_link CONNECT TO c##remote_clone_user IDENTIFIED BY "W3lc0m3#W3lc0m3#" USING 'FSI1';
Database link created.
SQL>
SQL> set timing on
SQL> create pluggable database CDB1PDB114G_FULL from FSI1PDB114G@clone_link;
Pluggable database created.
Elapsed: 00:02:14.01
SQL> alter pluggable database CDB1PDB114G_FULL open;
Pluggable database altered.
Elapsed: 00:00:16.76
SQL>
SQL> create pluggable database CDB1PDB114G_SNAP from FSI1PDB114G@clone_link SNAPSHOT COPY;
Pluggable database created.
Elapsed: 00:00:12.08
SQL> alter pluggable database CDB1PDB114G_SNAP open;
Pluggable database altered.
Elapsed: 00:00:14.37
SQL>
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 CDB1PDB1 READ WRITE NO
4 CDB1PDB114G_FULL READ WRITE NO
5 CDB1PDB114G_SNAP READ WRITE NO
SQL>
SQL> select con_id, sum(bytes)/1024/1024/1024 as size_gb from v$datafile where con_id in(4, 5) group by con_id;
CON_ID SIZE_GB
---------- ----------
4 113.907593
5 113.907593
Elapsed: 00:00:00.06
SQL>
So, fast cloning works if PDBs are in the same container and even if they are in different CDB’s. Above, the clone worked in a similar time as doing inside the same container because, when the SNAPSHOT COPY command is triggered, the Exascale software interpretates and clones directly at the storage level. The pointer to the mapping table of extents (the buckets) is added. When the source PDB modifies a datafile block, the new version is created and the cloned PDB(s) continues to see only the old image of block/extend. This is just a condensed description of what happens internally in Exascale software.
Until this moment, the snapshot clone works (whatever the database) if the CDBs are in the same Exascale Vault. The clone works for the entire full CDB as well, but in this case, more steps are needed (like new nid). The source of the clone can be the Data Gaurd Standby database as well.
Exascale, Management
As discussed before, with Exascale there is no more ASM, so, no more sqlplus connection with SYSASM and ASMCD. For now, there are two new important tools:
- XSH: Useful to manage the content of the Vault. Like, copy and remove files.
- ESCLI: The powerful tool, used to administrate the Exascale. It is similar to exacli for ExaCC. Can be used to create the Vault, Storage Pool, and users by example.
Below are some examples of xsh that can be useful in daily tasks.
List details of Vault (similar to asmcd lsdg command):
[oracle@lin11 ~]$ xsh ls @hVvMQYTk --detail name createTime createdBy flashCacheProv flashLogProv iopsProvEF iopsProvHC spaceProvEF spaceProvHC spaceUsedEF spaceUsedHC xrmemCacheProvEF xrmemCacheProvHC acl @hVvMQYTk Feb 19 22:25:08 2024 escssvcops unlimited true 0 72320 0 6597069766656 0 5613863531100 0 unlimited escssvcops:M;FBDVISTFBQJPGJAN6W2ESPQ:R;WTPND9HCBO5P8QGASKJHJGDPW:R [oracle@lin11 ~]$
Checking details of one file:
[oracle@lin11 ~]$ xsh ls @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/FSI1/195C48B6278590A6E0636039010ACC99/DATAFILE/TBSLOAD.OMF.53B95414 --detail name createTime usedBy size blockSize fileType redundancy contentType media @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/FSI1/195C48B6278590A6E0636039010ACC99/DATAFILE/TBSLOAD.OMF.53B95414 May 26 17:05:16 2024 9fb1bf8ffc57cf4dbfca211a3c47b3d1:SIM1 625991491584 8192 DATAFILE high DATA HC [oracle@lin11 ~]$
List files for one DataSet (wildcards can be used):
[oracle@lin11 ~]$ xsh ls @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/%CDB1STB% @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/CDB1STB/0454765FDBD85262E0631C284664D815/DATAFILE/SYSAUX.OMF.44140F45 ... ... @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/CDB1STB/ONLINELOG/group_8.OMF.57D66C8D @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/CDB1STB/PARAMETERFILE/spfile.OMF.1BBE70F8 @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/CDB1STB/PASSWORD/pwdCDB1STB.0AF4D3A8 @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/CDB1STB/TEMPFILE/TEMP.OMF.3CBAA28C [root@lin11 ~]#
Removing files (wildcards can be used to delete several files at the same time):
[oracle@lin11 ~]$ xsh rm @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/%CDB1STB% [oracle@lin11 ~]$
As discussed before, no more ASM, but the CRS still exists. So, the information from VOTEDISK and OCR can be retrieved as before:
[oracle@lin11 ~]$ crsctl query css votedisk
## STATE File Universal Id File Name Disk group
-- ----- ----------------- --------- ---------
1. ONLINE 09244fc460384f82bf1bd0bbf170b28b (@hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/vfile1) []
Located 1 voting disk(s).
[oracle@lin11 ~]$
[oracle@lin11 ~]$ ocrcheck
Status of Oracle Cluster Registry is as follows :
Version : 4
Total space (kbytes) : 569748
Used space (kbytes) : 85000
Available space (kbytes) : 484748
ID : 878048725
Device/File Name : @hVvMQYTk/SIM1-CRS-9FB1BF8FFC57CF4DBFCA211A3C47B3D1/data.ocr
Device/File integrity check succeeded
Device/File not configured
Device/File not configured
Device/File not configured
Device/File not configured
Cluster registry integrity check succeeded
Logical corruption check bypassed due to non-privileged user
[oracle@lin11 ~]$
Summary
It is clear, the Exascale is a game-changer. Being possible to clone PDBs and entire CDBs in a fast and secure way will facilitate a lot. Imagine all the actual work to do lift and shift, pipelines, and CI/CD to release one environment. Even using traditional storage (non-Exadata), a lot of commands are needed to avoid the datafile fuzziness, like the rman “snapshot time” for recovering the database, and other controls to check when the storage snapshot was made.
Now, with Exascale, there is a proper way to do snapshots for Engineered Systems. And this is just one small part of Exascale, a lot of new features are there. Block devices can be created and exported to Linux using iSCSI. Fine-tuned IORM can be deployed to control if one database can use or not flash by example. And environments can be scaled from a few to hundreds of TB’s. The limitation from growing from quarter, half, full, and elastic Exadata does not exist anymore.
Exascale is that, a lot of new features build up over and solid Exadata. With the launch of Exadata Exascale blogs and notes will start to appear, for now, check the:
- Exadata page.
- Exascale Architecture
- Exadata Blog.
- Launch video from Exadata Exascale.
- Provisioning Exadata Exascale at OCI Cloud.
Disclaimer: “The postings on this site are my own and don’t necessarily represent my actual employer positions, strategies, or opinions. The information here was edited to be useful for general purposes, and specific data and identifications were removed to allow reach the generic audience and to be useful for the community. Post protected by copyright.”
Disclaimer #2: “This post was possible due to the availability of Exadata Exascale and the participation in the Beta Program. Thank you for the opportunity Oracle Team. This post is not marketing or requested by Oracle. It is a personal opinion”.
Pingback: How to Monitor the Available Space on Exascale Storage Vault using SQL Query on Oracle Database 23ai – Blog do Dibiei