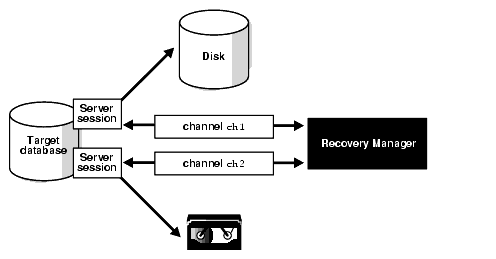
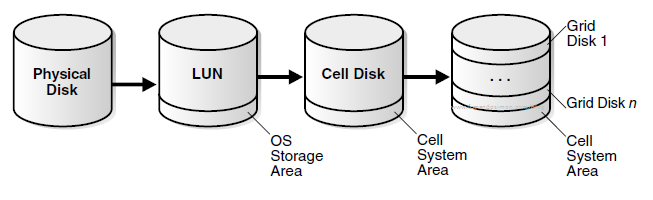
Oracle Zero Data Loss Recovery Appliance (ZDLRA) deliver to you the capacity to improve the reliability of your environment in more than one way. You can improve the RPO (Recovery Point Objective) for your databases until you reach zero, zero data loss. And besides that, adding a lot of new cool features (virtual backups, real-time redo, tape and cloud, DG/MAA integration) on the way how you do that your backups (incremental forever), and backup strategy. And again, besides that, improve the MAA at the highest level that you can hit.
But this is just marketing, right? No, really, works pretty well! My history with ZDLRA starts with Oracle Open World 2014 when they released the ZDLRA and I watched the session/presentation. At that moment I figure out how good the solution was. In that moment, hit exactly the problem that I was suffering for databases: deduplication (bad dedup). One year later, in 2015 at OOW I made the presentation for a big project that I coordinate (from definition implementation, and usage) with 2 Sites + 2 ZDLRA + N Exadata’s + Zero RPO and RTO + DG + Replication. And at the end of 2017 moved to a new continent, but still involved with MAA and ZDLRA until today.
This post is just a little start point about ZDLRA, I will do a quick review about some key points but will write about each one (with examples) in several other dedicates posts. I will not cover the bureaucratic steps to build the project like that, POC, scope definition, key turn points, and budget. I will talk technically about ZDLRA.