Recentemente estava acompanhando um problema que não era específico de banco de dados, mas muito relacionado com o dia a dia de um DBA. Aqui, o ambiente era VMware mas ele não era o problema, ele estava no Storage. Na realidade o problema não era o Storage em si, mas escolhas erradas que foram feitas na sua utilização.
Resumidamente as equipes reclamavam que as vezes ficava “tudo lento”. Não era um ambiente de “produção”, mas sim um ambiente para que equipes de desenvolvimento tenham bancos de dados para testes (Oracle, SQL Server, DB2) e servidores de aplicação (JBoss, Apache). Tudo isso sobre VMware ESXi 4.1 e 5.0 e um Storage EMC (série VNX).
Depois dos relatos das equipes comecei a investigar e observei que pelos gráficos de desempenho do VMware o consumo de CPU estava abaixo de 50% para o host físico, mas algumas coisas estavam estranhas com o disco e o datastore. No VMware cada host físico e máquina virtual tem uma aba de performance onde temos acessos a diversos gráficos de desempenho (se você estiver usando o vCenter, mude os gráficos para Realtime) e eles estavam fora do padrão. Acredito que outros players de virtualização tenham métodos semelhantes para análise.
Nesta aba, temos a opção “Switch to” onde podemos acessar diversos gráficos indo desde CPU até consumo de energia. Aqui não existia qualquer problema de CPU, ocorria sobra de 60%. Passando para o gráficos “Datastores” a latência no acesso apresentava valores superiores a 400ms, coincidentemente no mesmo momento que as equipes reclamavam. O mais intrigante é que não haviam consumos exacerbados de discos pelos outros hosts e máquinas virtuais. O consumo de discos (KB/s) você pode ver através do gráfico “Disks”, caso seja storage o VMware apresenta o consumo sobre cada lun disponível. Aparentemente não existia uma relação direta entre o consumo (KB/s) e a latência. Em alguns momentos existiam consumos médios 100MB/s e latências menores que 25ms, em outros 8MB/s e latências de 250ms.
Isso levou a desconfiar de um vilão muitas vezes esquecido o IOPS. O cálculo de IOPS leva a conta de quantas operações de entrada e saídas (I/O) são feitas por segundo. Muitas vezes ele passa despercebido e nem é computado, nos preocupamos somente com quantidade (MB) e velocidade (MB/s). Infelizmente no ambiente em questão não tinha uma forma direta de calcular os IOPS, nenhum gráfico do VMware entrega esta informação. Felizmente algumas pesquisas no Google levaram a uma forma de gerar a contagem de IOPS através do VMware.
Para isso precisamos criar um gráfico novo através da opção “Chard Options…” da aba “Performance” do VMware. Ao clicarmos somos direcionados a uma tela com diversas opções que podem ser medidas, ali encontramos no menu “Chard Options” a informação “Disk” e depois “Real-Time”. A imagem abaixo reflete isso:
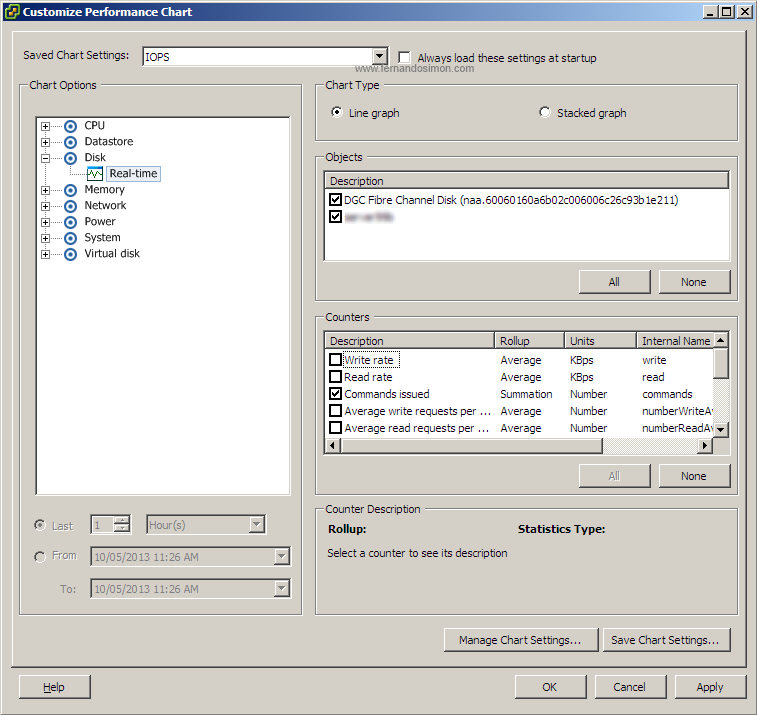
Aqui temos “Real-Time” selecionado e em “Objects” podemos escolher as luns ou discos para análise (caso esteja na aba de Performace de uma máquina virtual aparecerão somente as lus que esta acessa, para o host aparecem todas). Para gerar o gráfico de IOPS temos que selecionar as opções corretas em “Counters”, ali devemos deixar marcados 3 opções: Write requests, Read requests e Commands issued. Todas as outras opções devem ficar desmarcadas. Se optarmos por salvarmos (o que eu recomendo) basta clicar em “Save Chart Settings” e escolhemos o nome.
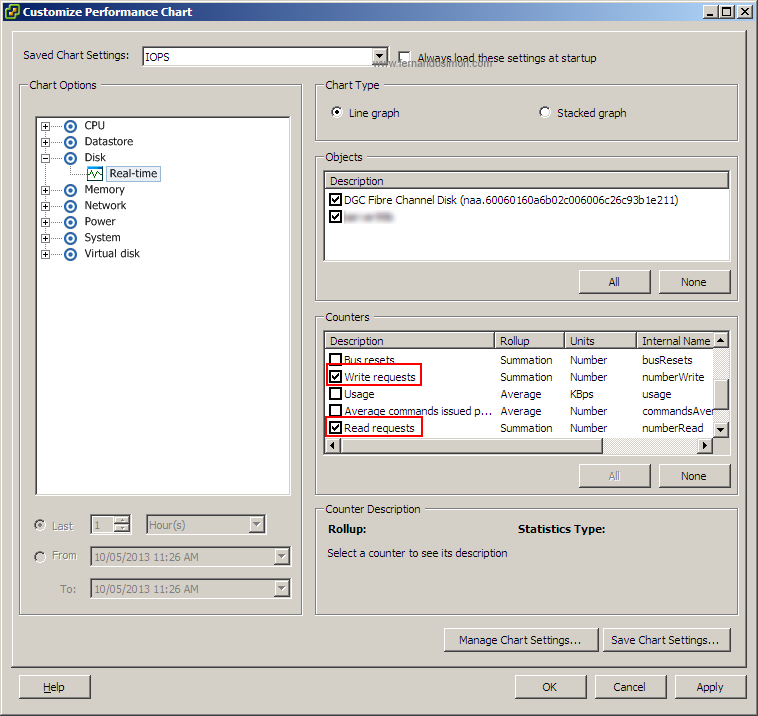
Assim teremos um gráfico de IOPS com a quantidade de escrita e leitura que foram enviadas pelo VMware, também teremos a quantidade total (Commands Issued, somatório de escrita e leitura) dada pelo próprio VMware. Podemos fazer isso para cada máquina virtual, e recomendo caso você tenha suspeita em uma específica.
Com este gráfico em mão podemos voltar ao problema e identificar o que estava acontecendo. Existia um relatado de evento aleatório, não tinha horário definido e a duração variava também. Como citado acima, os gráficos de CPU e disco não revelavam muito, só a latência indicava o problema. Colocando o gráfico de IOPS tudo começou a se encaixar.
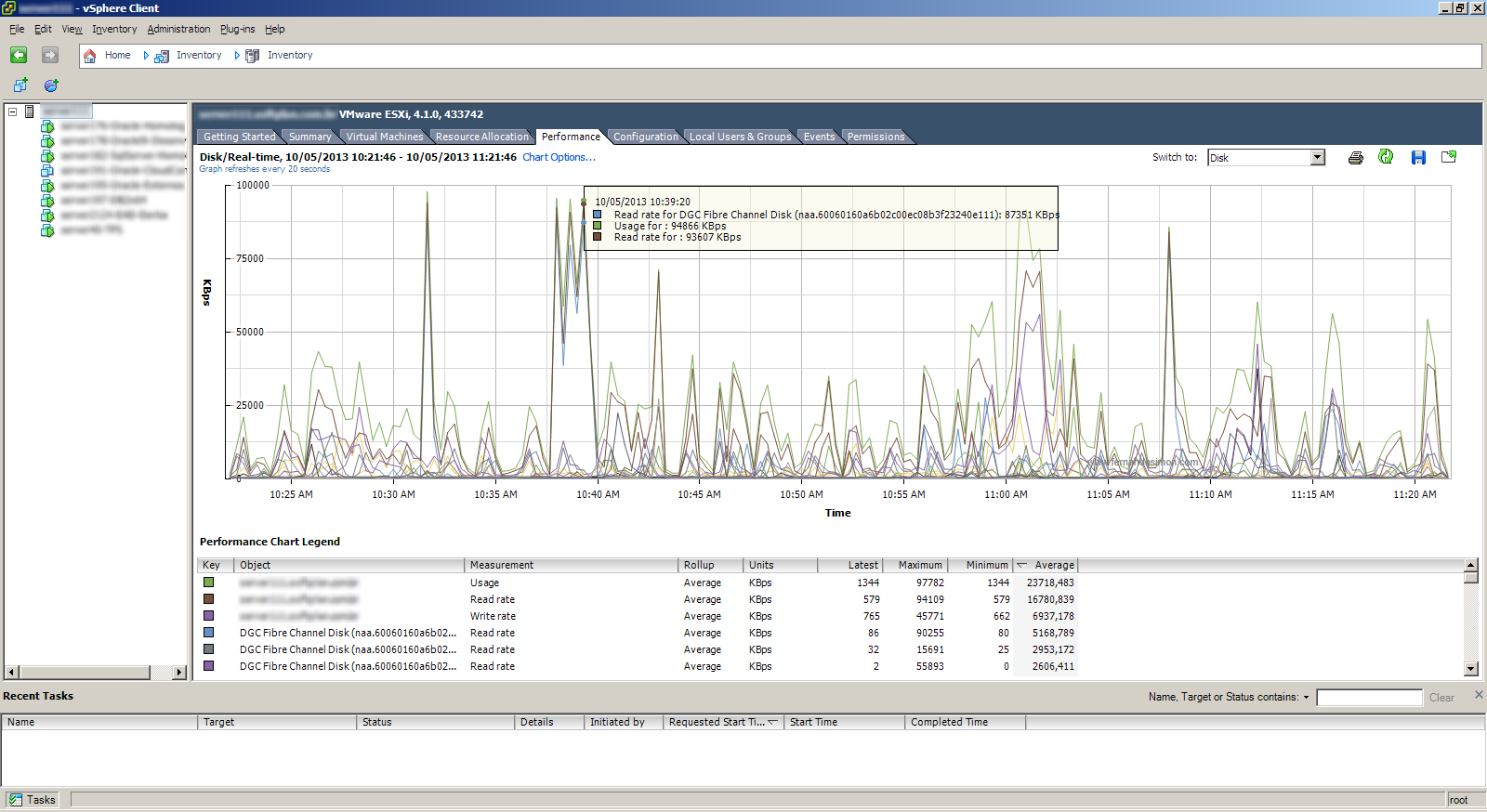
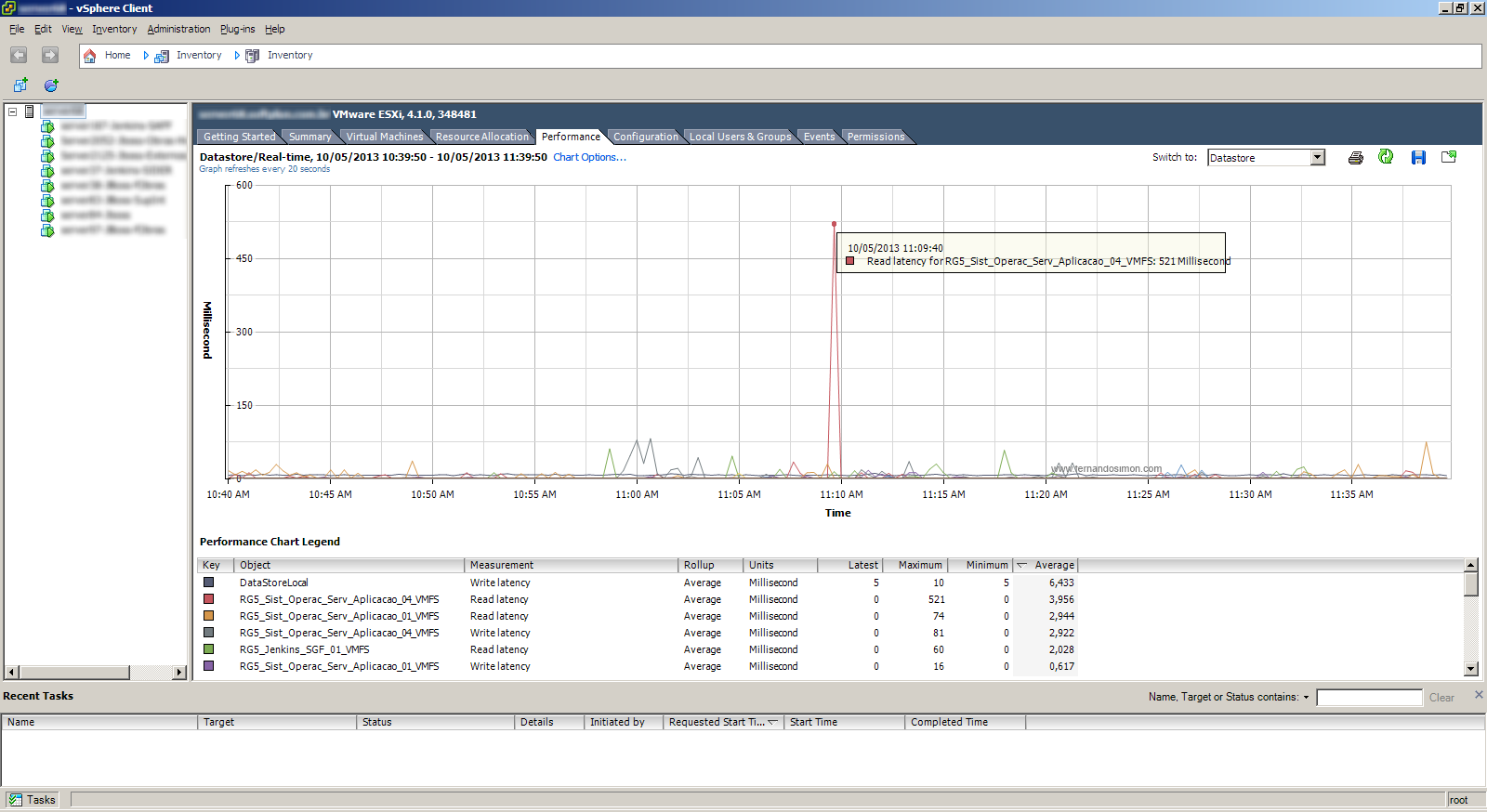
Antes temos que interpretar o gráfico, na figura abaixo podemos identificar alguns pontos importantes, ela nos mostra que para este servidor as 10:39:20 ele estava fazendo próximo de 100MB/s. Duas informações importantes aqui, a primeira é em ralação a unidade de medida, ela está em KBps e isso quer dizer KB/s, não devemos confundir com Kbps (isso está definido no manual do VMware). A segunda informação é com o período do gráfico, ele é gerado a cada 20 segundos.
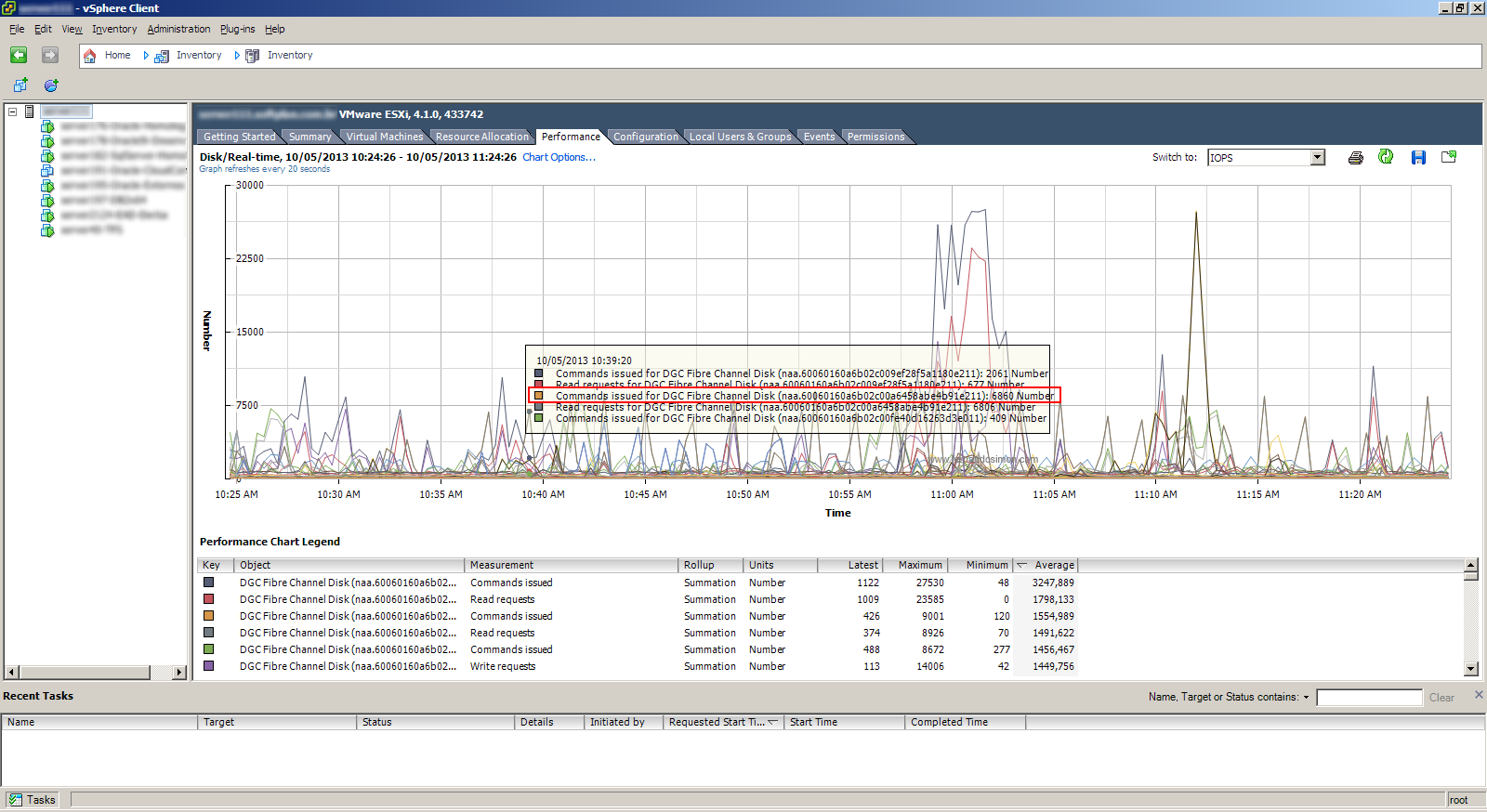
Na imagem abaixo podemos observar que o mesmo horário gerou um total de 6806 requisições (marcado em vermelho). Aqui o detalhe, como ele é uma sumarização isso que dizer que em 20 segundos ele gerou essa quantidade e dividindo 6860 por 20 chegamos a 343 IOPS (agora sim, por segundo). É imprescindível que você saiba as luns ou os discos que você quer analisar, os gráficos para o host físico são mais confusos por apresentarem todas as luns. Além disso, sempre verifique como o gráfico apresenta os resultados, se forem sumarizados divida pelo tempo de exposição (20 segundos). O pico de quase 30000 requisições que aparece na mesma imagem explicarei mais abaixo.
Conseguindo interpretar o gráfico podemos investigar mais a raiz do problema. Na imagem abaixo observe o pico de 521ms de latência no acesso a disco (observe que isso é médis em 20 segundos) proveniente do host (chamado de Host A).
Indo atrás do vilão, no mesmo momento em outro host (o Host B) existia uma máquina virtual (chamada de Máquina X) que estava gerando uma grande quantidade de requisições. Na imagem abaixo temos picos de requisições, chegando a um valor superior a 11000 (9000 de escrita e 2000 de leitura) sumarizados a cada 20 segundos (11000/20=550 IOPS). Infelizmente na imagem a hora dos dois hosts estava fora de sincronia, mas elas foram retiradas no mesmo momento. No ponto selecionado ela estava fazendo aproximadamente uma média 9000 I/O e isso nos dá 450 IOPS.
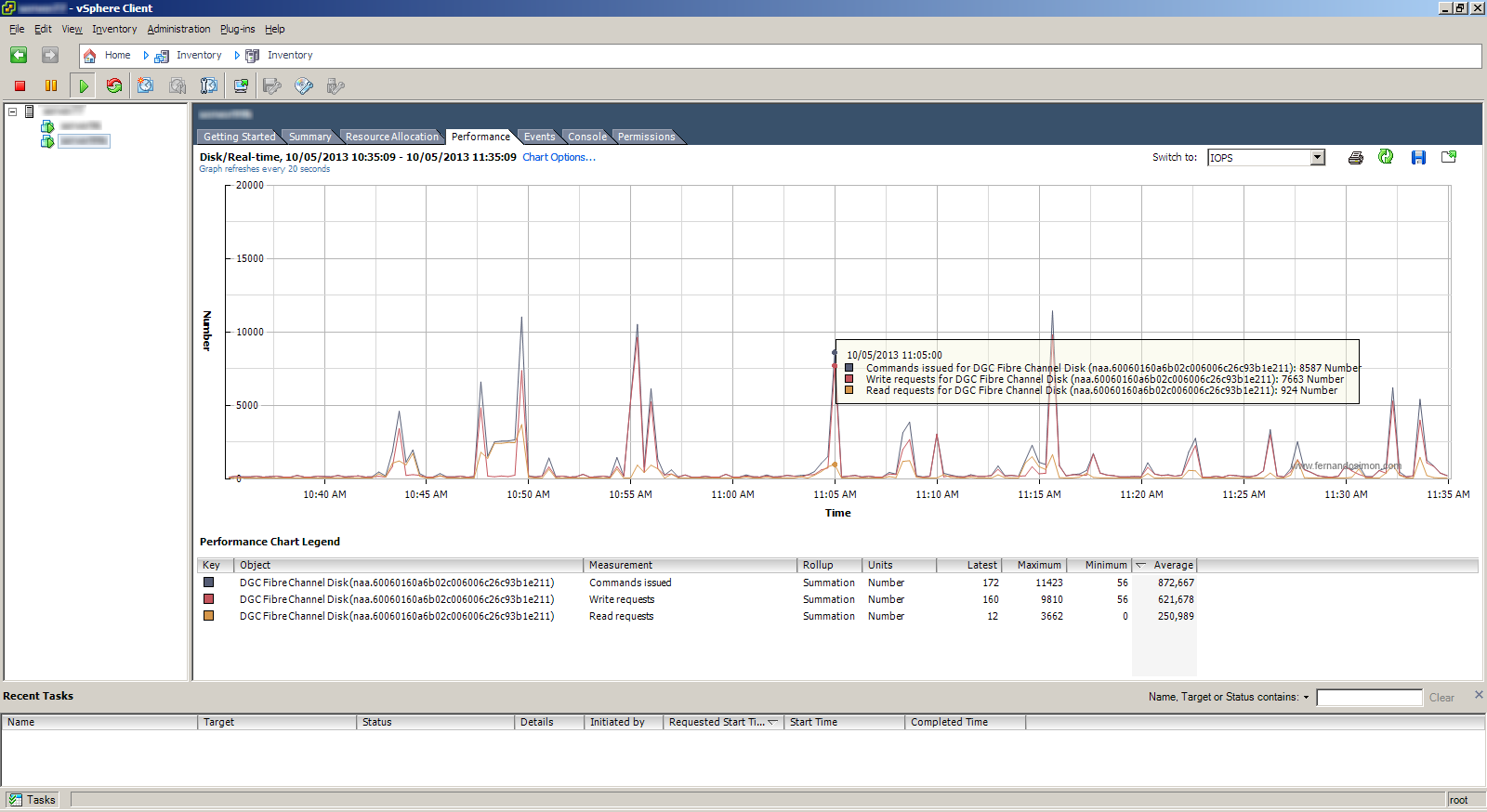
Sobrepondo as duas imagens observa-se que elas ocorrem no mesmo momento, quando a Máquina X fez o pico de I/O selecionado na imagem o Host A detectou a latência. Isso nos mostra que os eventos estavam relacionados. Um detalhe interessante, observe que mesmo a Máquina X tendo gerado vários picos de IOPS somente um deles causou latência, isso ocorre porque nos outros picos não havia concorrência entre os hosts. Nenhuma outra máquina virtual do Host A tentou fazer escritas ou leituras pesadas no disco, só quando alguma máquina virtual do Host A precisou acessar o disco ela concorreu com a Máquina X.
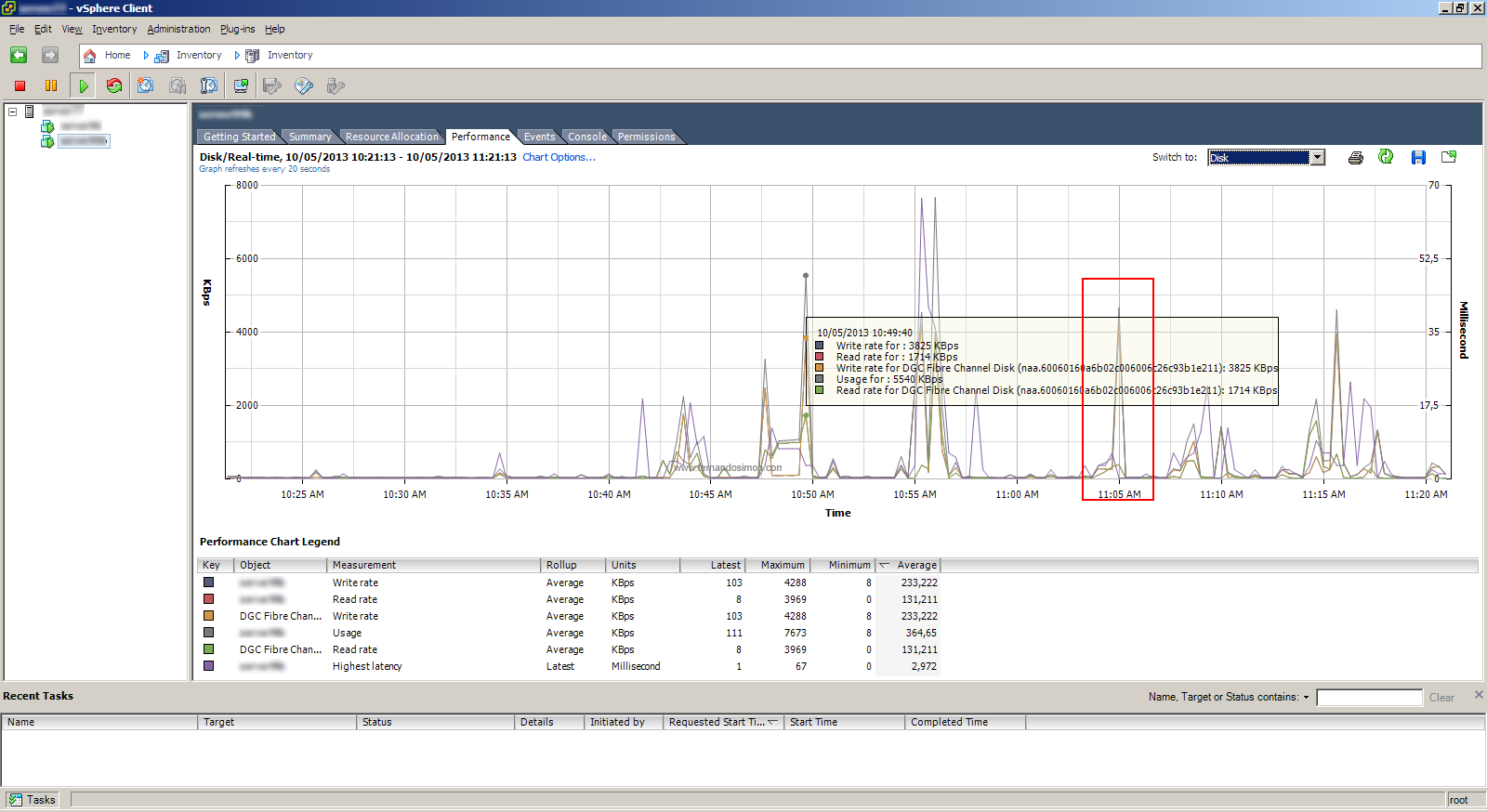
Infelizmente essa não era a origem do problema, existiam outros hosts e maquinas virtuais fazendo o dobro de requisições sem qualquer concorrência ou latência. Observe na imagem abaixo que para o mesmo momento que a Máquina X fez 550 IOPS ele estava consumindo somente 5MB/s. Esta imagem foi retirada alguns minutos antes das anteriores, mas observe no gráfico o momento próximo as 11:05 que está marcado em vermelho.
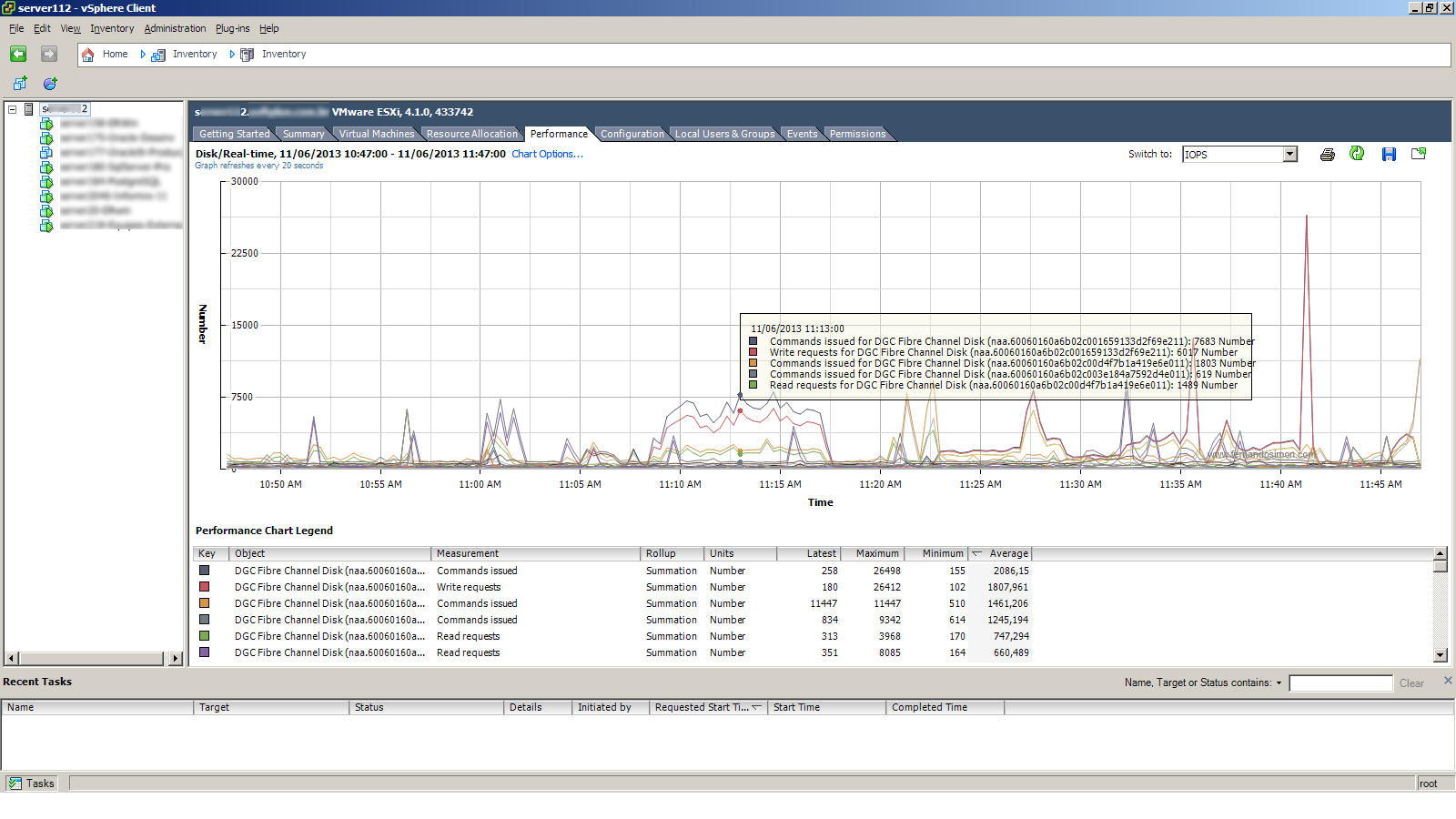
Abaixo outras imagens do mesmo problema que ocorreram em outros momentos (observe o nome dos hosts). Nas duas primeiras o mesmo host estava consumindo em torno de 140MB/s e aproximadamente 7600 IOPS (7600/20=380). Enquanto isso, na terceira imagem pode ser observado que outro host detectou lentidão de acesso.
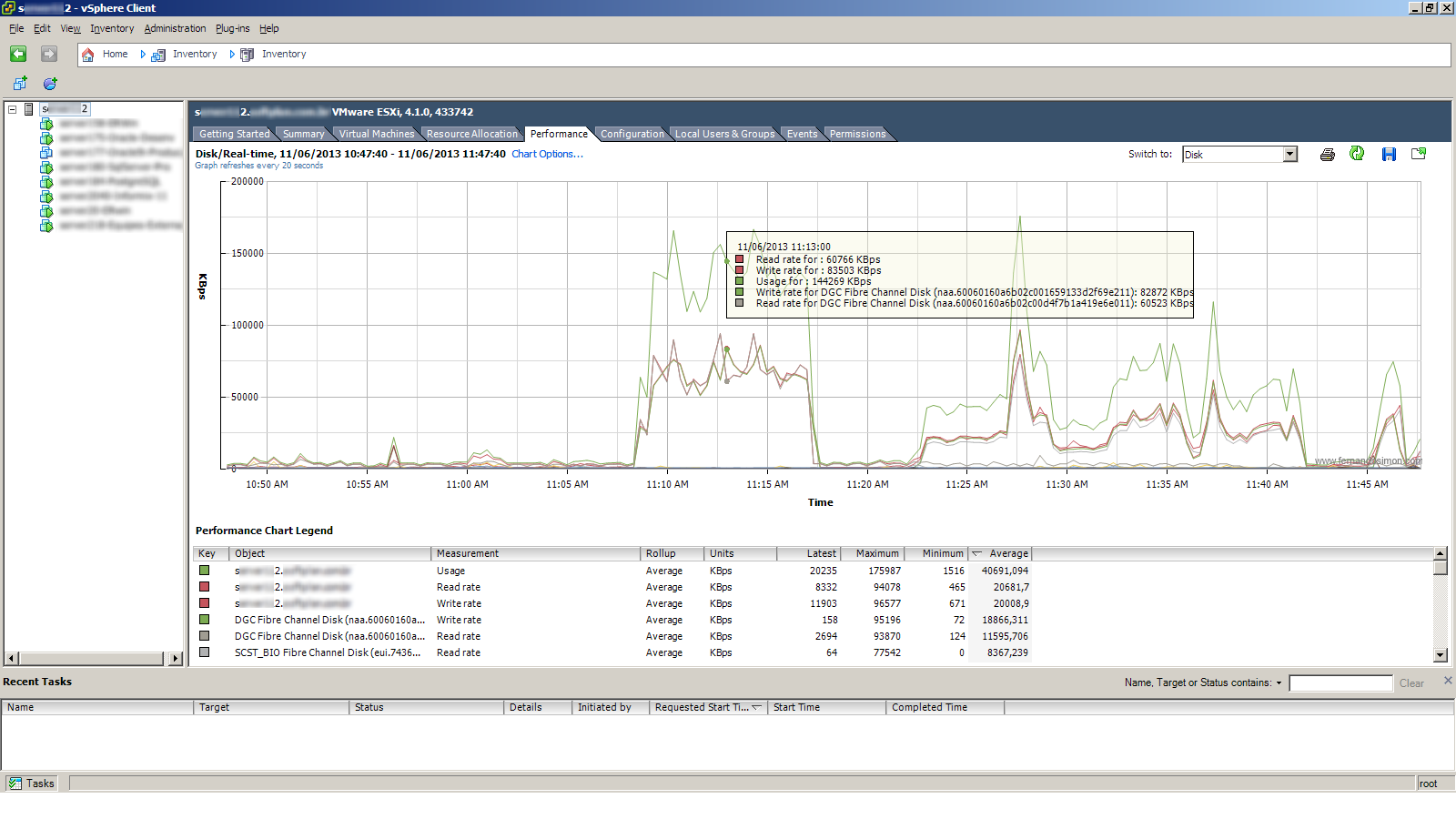
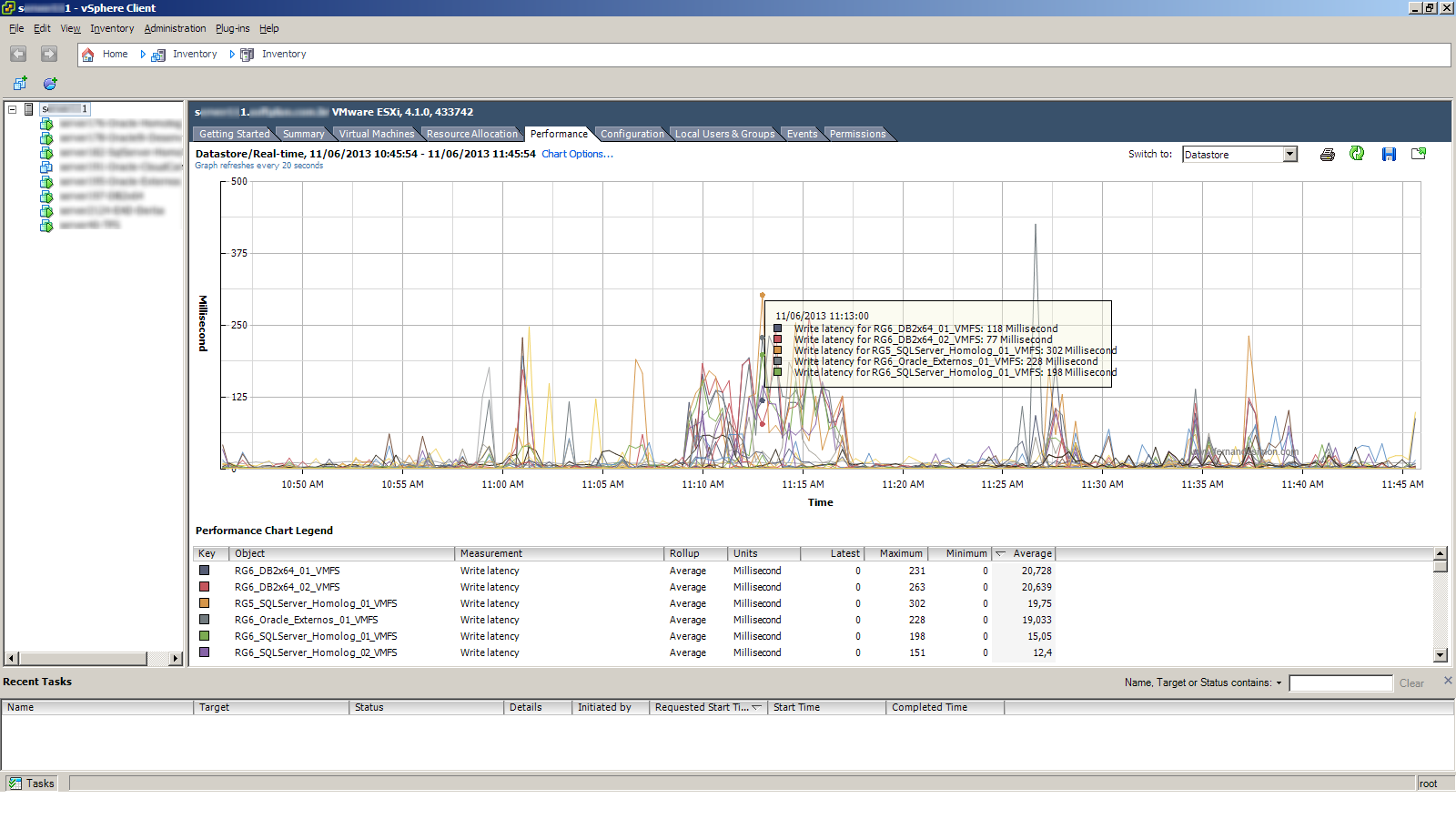
O que intrigou um pouco foi que tanto o Host A e a Máquina X do Host B não compartilhavam o datastore do VMware. As luns apresentadas do storage ao VMware eram diferentes, assim os datastores não eram compartilhados entre os servidores em questão. Analisando um pouco mais, percebemos que o compartilhamento estava em nível de Raid Group do Storage.
Quando trabalhamos com Storage algumas escolhas podem levar a problemas que não foram imaginados na concepção do ambiente. Neste caso em específico, ambos os Host A e a Máquina X estavam apoiados sobre um Raid Group 5 formados por 6 discos SATA de 2TB de 7,200rpm. E esse era o problema, nada de VMware ou storage e sim discos. A opção de utilizar discos SATA de 7,200 rpm era o problema. Aqui está a peça que faltava e juntava o quebra-cabeça.
Discos SATA de 7,200 rpm nos dão no máximo 80 IOPS, existem diversos links na Internet comentando sobre isso, com fórmulas para calcular o IOPS de cada disco. Das diversas existentes eu recomendo a leitura da série de artigos do Joshua Townsend sobre IOPS e Storage, aqui, aqui e aqui
Como um disco SATA entrega aproximadamente 80 IOPS, um Raid Group com 6 discos disponibilizará aproximadamente 500 IOPS. Aqui não estamos considerando algumas informações relativas ao RAID, como penalidade de escrita e caches de leitura do storage, só uma conta básica para facilitar e não prolongar ainda mais o texto.
Voltando ao problema, agora temos a sua origem detectada. A Máquina X estava consumindo todo o IOPS do Raid Group. Se você observar irá perceber que a Máquina X fez mais IOPS que o Raid Group consegue entregar, temos que levar em consideração que IOPS de leitura geralmente são otimizados pelos cachês que temos nesta pilha (Storage/Controladora/VMware).
Assim, quando qualquer outra máquina virtual fosse tentar qualquer I/O sobre alguma lun deste Raid Group iria ter latência no acesso. Mesmo as máquinas virtuais não compartilhando o datastore elas concorrem pelo mesmo disco, suas luns podem apontar para o mesmo Raid Group no Storage. E isso não é um problema do Storage, aqui foi um escolha no momento de adquirir os discos SATA de baixa performance. Provavelmente a equipe no momento de adquirir o Storage não levou em consideração IOPS, somente se preocupou com MB/s e espaço disponível.
As 30000 requisições em 20 segundos de algumas imagens acima (30000/20=1500 IOPS), elas foram alcançadas pois a sua lun estava apoiada sobre um Raid Group de discos SAS de alta capacidade (aproximadamente 200 IOPS cada disco). Repare na mesma imagem que o consumo (MB/s) é praticamente o mesmo nos dois momentos. Discos diferentes, desempenhos diferentes.
Nos artigos do Joshua Townsend citados acima existem informações importantes, como o método para calcular o IOPS para cada disco, o método para identificar quantos discos são necessários para entregar o IOPS desejado e recentemente quantos discos para disponibilizar os MB/s. Se tiver interesse em detalhes mais técnicos o artigo escrito por Duncan Epping aqui é fundamental, o importante deste artigo está em seus comentários. Lá temos informações postadas por pessoas diretamente da EMC e Netapp.
Por fim, a causa do problema estava em camadas mais baixas do ambiente. Geralmente não calculamos os limites que do nosso ambiente pode alcançar, e o IOPS pode ficar esquecido. Espaço em disco e MB/s são importantes, mas o IOPS também.
A solução do problema vai depender do seu ambiente, se a aplicação que está consumindo o IOPS não puder ser revista (por exemplo uma query na base de dados) você terá que mover os dados ou dedicar mais recursos para seu ambiente, não tem como fugir. Caches maiores auxiliam principalmente na leitura, na escrita não. Raid groups maiores podem ajudar, mas o custo de escrita ou cálculo da paridade no caso de falha podem ser proibitivos. Não existe solução milagrosa, é identificar o problema e tentar achar uma que atenda as suas necessidades.
Observe que nas imagens acima nem sempre quanto mais MB/s mais IOPS você faz. Ler ou escrever 10GB em blocos de 8Kb podem ter menos impacto do que 100 mil escritas de 1k. Muitas vezes temos que expandir o nosso horizonte de busca, não podemos culpar só a aplicação. Temos que levantar todos os dados possíveis para apontar os problemas e principalmente as soluções. Na maioria das vezes a economia de recursos (por exemplo em escolher SATA ao invés de SAS) sempre traz seus reflexos.
Documento muito interessante! Foi de grande valia argumentativa!
Excelente matéria e muito bem explicada. Esclareceu o entendimento sobre o assunto.
Parabéns!
Muito bom o artigo.
Excelente artigo e muito esclarecedor. Obrigado por compartilhar!!
Excelente artigo! Parabéns, obrigado por compartilhar, sucesso!!!